
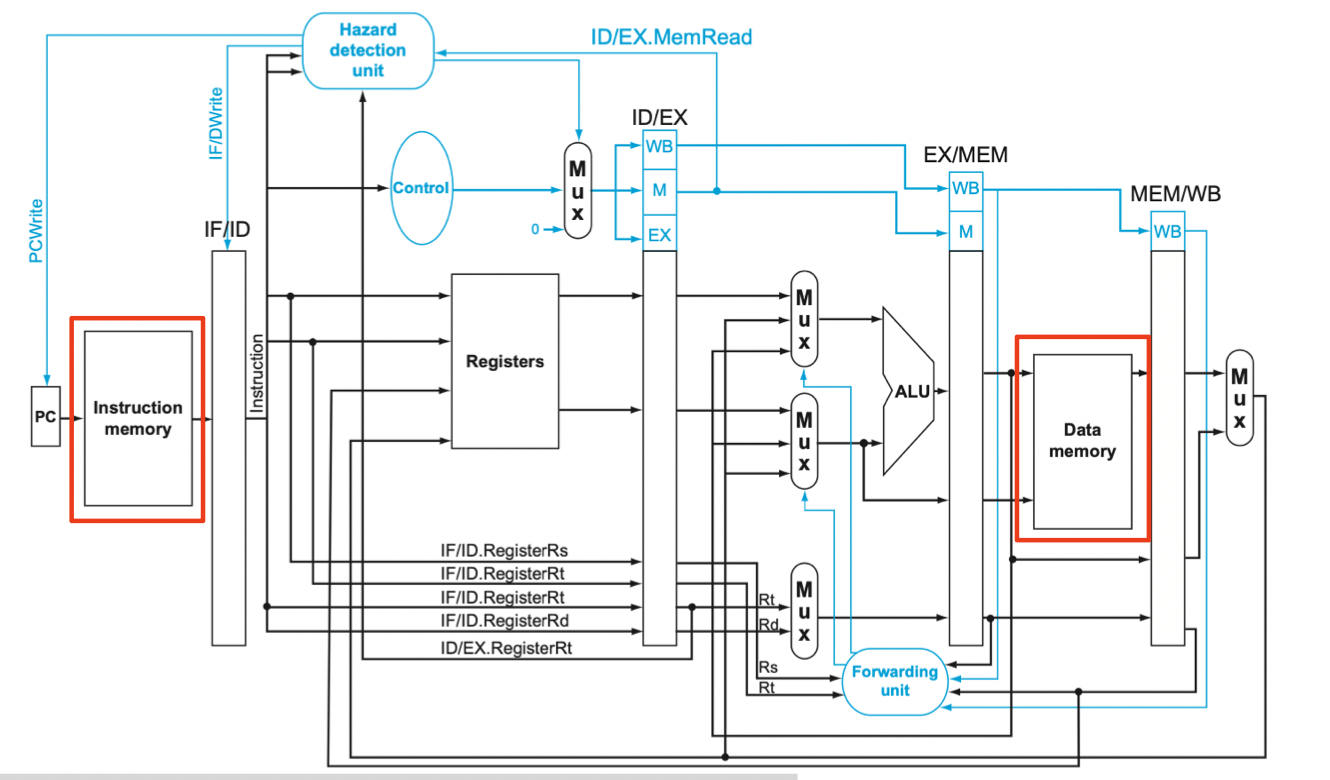
모든 데이터(위 이미지에서, Instruction memory와 Data memory)가 컴퓨터의 메모리에 저장된다. load와 store 명령어는 메모리에 액세스하여 데이터를 읽거나 쓴다. 이상적으로는, 프로그래머들은 무제한이고 빠른 메모리를 바란다.
현재의 메모리들인 SRAM, DRAM, SSD, HDD를 비교하면,
가격 : SRAM > DRAM > SSD > HDD
성능 : SRAM > DRAM > SSD > HDD
용량 : HDD > SSD > DRAM > SRAM
이 된다.
크고 빠른 메모리를 동시에 제공하는 단일 메모리는 없지만, 현대 컴퓨터는 크고 빠른 메모리의 illusion을 제공한다.
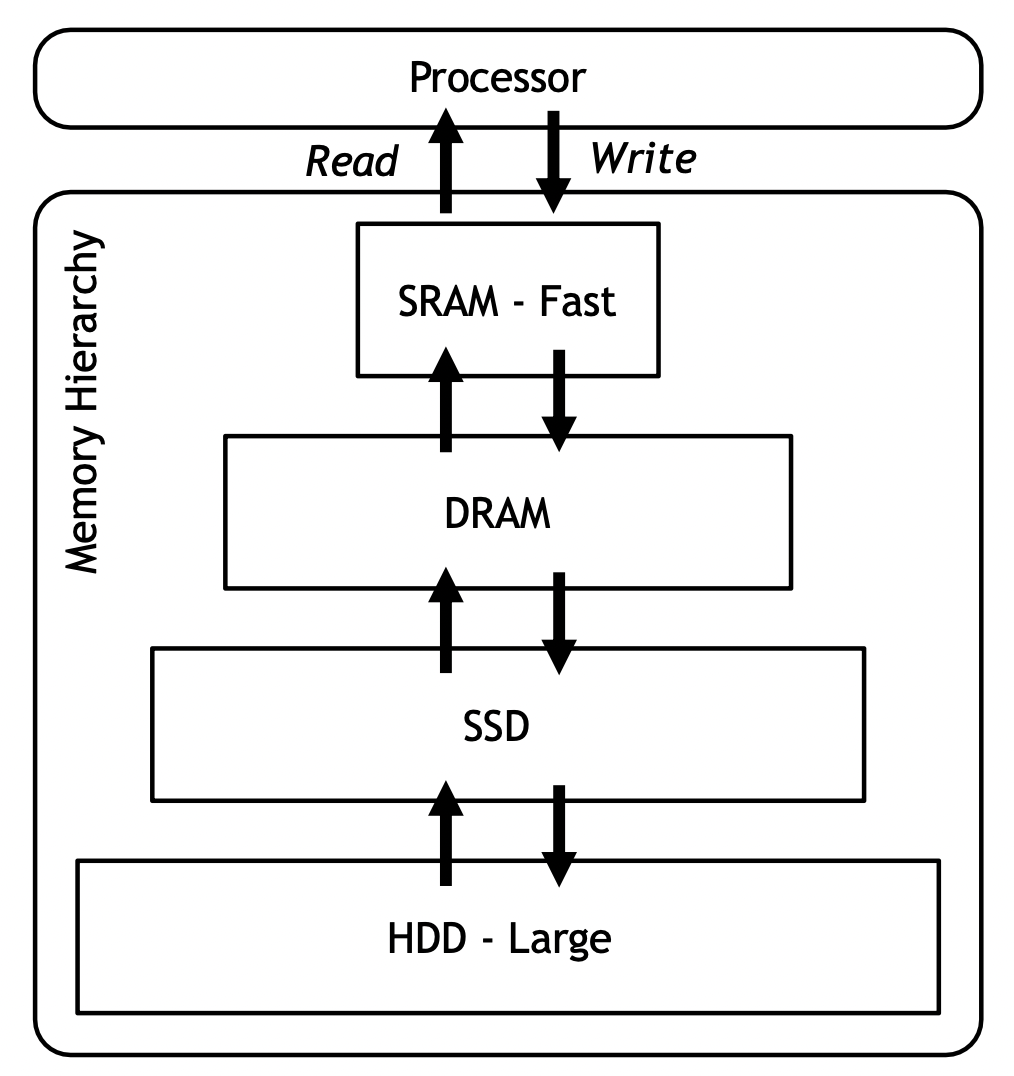
메모리 시스템은 계층(hierarchy)적인 방식으로 다양한 메모리 기술을 포함한다.
- 가장 낮은 레벨에서는 가장 크고 느린 메모리가 위치한다.
- 첫 번째 레벨에는 가장 빠르고 작은 메모리가 위치한다.
- 프로세서로부터 멀어질수록 크기와 액세스 시간이 증가한다.
데이터도 유사한 계층을 가지고 있다.
- 모든 데이터는 가장 낮은 레벨에 저장된다.
- 프로세서에 가까운 레벨은 일반적으로 더 멀리 떨어진 레벨의 subset이다. (SRAM에 있는 데이터는 DRAM에 있는 데이터에 포함됨)
- 가장 작은 subset은 첫 번째 레벨에 저장된다.
- 프로세서는 첫 번째 레벨의 subset data에만 직접 액세스할 수 있다.
프로세서가 레벨 1 메모리에만 직접 액세스할 수 있다면, 프로세서는 가장 빠른 메모리와 함께 작동하는 것처럼 느껴진다.
프로세서가 레벨n 메모리에 저장된 모든 data set에 액세스할 수 있다면, 프로세서는 가장 큰 메모리와 함께 작동하는 것처럼 느껴진다.
프로세서에 가까운 레벨일 수록 더 멀리 있는 레벨의 subset인 것은 메모리 액세스에서 locality 원칙에 기반한다.
Temporal locality (시간적 지역성)
- 데이터 항목이 참조되면 곧 다시 참조될 가능성이 높다. (반복문에서 반복 변수가 다시 참조됨)
Spatial locality (공간상의 지역성)
- 항목이 참조되면 주소가 가까운 항목들도 곧 참조될 가능성이 높다. (배열에서 이웃한 요소가 함께 참조됨)
- 따라서 이웃한 데이터 항목을 상위 레벨에 저장하면 액세스 시간을 줄일 수 있다.
계층 구조(hierarchy)의 모든 레벨 쌍은 상위 레벨과 하위 레벨로 간주될 수 있다. 즉, 데이터는 한 번에 인접한 두 레벨 사이에서만 복사된다.
두 레벨에서 존재하거나 존재하지 않을 수 있는 최소한의 정보 단위를 block, 또는 line이라 한다.
프로세서가 요청한 데이터가 상위 레벨의 어떤 block에 있을 경우 이를 hit라 한다.
상위레벨 메모리에 액세스하는데 걸리는 시간을 hit time이라 한다.
데이터가 상위레벨에 없다면 이를 miss라 한다. 이 때, 데이터는 하위 레벨에서 상위 레벨로 복사되어 읽힌다.
이 때의 전체 시간은 miss penalty라 한다.
hit ratio는 상위 레벨에서 찾은 액세스의 분수이다. 히트 비율이 높을 수록 성능이 높아진다.
miss ratio = 1 - hit ratio
우리는 가장 상위 레벨의 두 메모리, 즉 SRAM(캐시)와 DRAM(메인메모리)에 초점을 맞출 것이다.
캐시에 저장된 데이터는 캐시와 메인메모리 사이에서 데이터를 전송하며 변경된다.
Direct Mapped Cache
Direct Mapped Cache는 각 메모리 위치는 캐시에 한 위치에 직접 매핑되는 것을 뜻한다.
각 데이터 항목이 캐시의 정확히 하나의 위치에 들어갈 수 있다면, 캐시에 데이터 항목이 있는지 확인하는 것은 간단하다.
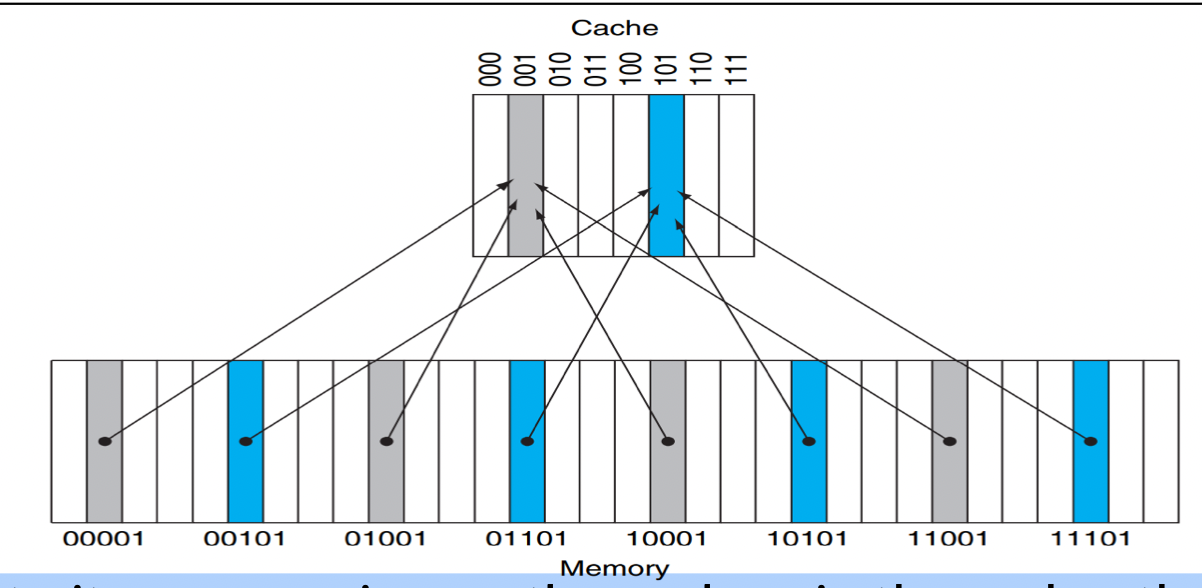
각 데이터 항목에 캐시 내의 위치가 할당된다.
메모리 내 데이터 항목의 주소를 기반으로 캐시 위치가 할당된다.
여기서 한 캐시 위치에 여러 데이터 항목이 할당된다.
8개의 캐시 블록은 32개의 데이터 항목에 할당돼야한다.
하나의 캐시 블록에는 4개의 서로 다른 데이터 항목이 배치될 수 있다.
메모리의 하위 3비트에 해당하는 캐시의 자리에 메모리를 할당한다.
캐시 위치는 다른 메모리 위치의 데이터 항목을 포함할 수 있다.
요청된 데이터가 캐시의 데이터와 일치하는지 알기 위해 각 캐시 위치에 tag를 추가할 수 있다.
메모리 주소의 하위 비트는 캐시 위치를 식별하는데 사용하고, 상위비트는 특정 데이터를 식별하는데 사용된다.
여기서 하위 비트는 index, 상위 비트는 tag라고 한다.
캐시 블록은 항상 유효한(valid) 데이터를 가지고 있는 것은 아니다.
캐시 블록에 네 개의 데이터 중 어떤 데이터도 없을 수도 있다.
이를 해결하기 위해 각 캐시 위치에 유효 비트(valid bit)를 추가할 수 있다.
- valid bit가 설정된 경우 캐시 위치에 valid data가 있으며, 그 다음 tag를 참조하여 원하는 데이터인지 확인한다.
- valid bit가 설정되지 않은 경우, invalid이므로 tag를 확인하지 않는다.
'학교강의필기장 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조[21]: Direct Mapped Cache for the Real World (0) | 2023.06.22 |
|---|---|
| 컴퓨터구조[20]: Access a Direct Mapped Cache (0) | 2023.06.22 |
| 컴퓨터구조[18]: Data Hazard - Stall (0) | 2023.06.22 |
| 컴퓨터구조[17]: Data Hazard - Data Forwarding (0) | 2023.06.22 |
| 컴퓨터구조[16]: control signals for pipelined datapath (0) | 2023.06.22 |
모든 데이터(위 이미지에서, Instruction memory와 Data memory)가 컴퓨터의 메모리에 저장된다. load와 store 명령어는 메모리에 액세스하여 데이터를 읽거나 쓴다. 이상적으로는, 프로그래머들은 무제한이고 빠른 메모리를 바란다.
현재의 메모리들인 SRAM, DRAM, SSD, HDD를 비교하면,
가격 : SRAM > DRAM > SSD > HDD
성능 : SRAM > DRAM > SSD > HDD
용량 : HDD > SSD > DRAM > SRAM
이 된다.
크고 빠른 메모리를 동시에 제공하는 단일 메모리는 없지만, 현대 컴퓨터는 크고 빠른 메모리의 illusion을 제공한다.
메모리 시스템은 계층(hierarchy)적인 방식으로 다양한 메모리 기술을 포함한다.
- 가장 낮은 레벨에서는 가장 크고 느린 메모리가 위치한다.
- 첫 번째 레벨에는 가장 빠르고 작은 메모리가 위치한다.
- 프로세서로부터 멀어질수록 크기와 액세스 시간이 증가한다.
데이터도 유사한 계층을 가지고 있다.
- 모든 데이터는 가장 낮은 레벨에 저장된다.
- 프로세서에 가까운 레벨은 일반적으로 더 멀리 떨어진 레벨의 subset이다. (SRAM에 있는 데이터는 DRAM에 있는 데이터에 포함됨)
- 가장 작은 subset은 첫 번째 레벨에 저장된다.
- 프로세서는 첫 번째 레벨의 subset data에만 직접 액세스할 수 있다.
프로세서가 레벨 1 메모리에만 직접 액세스할 수 있다면, 프로세서는 가장 빠른 메모리와 함께 작동하는 것처럼 느껴진다.
프로세서가 레벨n 메모리에 저장된 모든 data set에 액세스할 수 있다면, 프로세서는 가장 큰 메모리와 함께 작동하는 것처럼 느껴진다.
프로세서에 가까운 레벨일 수록 더 멀리 있는 레벨의 subset인 것은 메모리 액세스에서 locality 원칙에 기반한다.
Temporal locality (시간적 지역성)
- 데이터 항목이 참조되면 곧 다시 참조될 가능성이 높다. (반복문에서 반복 변수가 다시 참조됨)
Spatial locality (공간상의 지역성)
- 항목이 참조되면 주소가 가까운 항목들도 곧 참조될 가능성이 높다. (배열에서 이웃한 요소가 함께 참조됨)
- 따라서 이웃한 데이터 항목을 상위 레벨에 저장하면 액세스 시간을 줄일 수 있다.
계층 구조(hierarchy)의 모든 레벨 쌍은 상위 레벨과 하위 레벨로 간주될 수 있다. 즉, 데이터는 한 번에 인접한 두 레벨 사이에서만 복사된다.
두 레벨에서 존재하거나 존재하지 않을 수 있는 최소한의 정보 단위를 block, 또는 line이라 한다.
프로세서가 요청한 데이터가 상위 레벨의 어떤 block에 있을 경우 이를 hit라 한다.
상위레벨 메모리에 액세스하는데 걸리는 시간을 hit time이라 한다.
데이터가 상위레벨에 없다면 이를 miss라 한다. 이 때, 데이터는 하위 레벨에서 상위 레벨로 복사되어 읽힌다.
이 때의 전체 시간은 miss penalty라 한다.
hit ratio는 상위 레벨에서 찾은 액세스의 분수이다. 히트 비율이 높을 수록 성능이 높아진다.
miss ratio = 1 - hit ratio
우리는 가장 상위 레벨의 두 메모리, 즉 SRAM(캐시)와 DRAM(메인메모리)에 초점을 맞출 것이다.
캐시에 저장된 데이터는 캐시와 메인메모리 사이에서 데이터를 전송하며 변경된다.
Direct Mapped Cache
Direct Mapped Cache는 각 메모리 위치는 캐시에 한 위치에 직접 매핑되는 것을 뜻한다.
각 데이터 항목이 캐시의 정확히 하나의 위치에 들어갈 수 있다면, 캐시에 데이터 항목이 있는지 확인하는 것은 간단하다.
각 데이터 항목에 캐시 내의 위치가 할당된다.
메모리 내 데이터 항목의 주소를 기반으로 캐시 위치가 할당된다.
여기서 한 캐시 위치에 여러 데이터 항목이 할당된다.
8개의 캐시 블록은 32개의 데이터 항목에 할당돼야한다.
하나의 캐시 블록에는 4개의 서로 다른 데이터 항목이 배치될 수 있다.
메모리의 하위 3비트에 해당하는 캐시의 자리에 메모리를 할당한다.
캐시 위치는 다른 메모리 위치의 데이터 항목을 포함할 수 있다.
요청된 데이터가 캐시의 데이터와 일치하는지 알기 위해 각 캐시 위치에 tag를 추가할 수 있다.
메모리 주소의 하위 비트는 캐시 위치를 식별하는데 사용하고, 상위비트는 특정 데이터를 식별하는데 사용된다.
여기서 하위 비트는 index, 상위 비트는 tag라고 한다.
캐시 블록은 항상 유효한(valid) 데이터를 가지고 있는 것은 아니다.
캐시 블록에 네 개의 데이터 중 어떤 데이터도 없을 수도 있다.
이를 해결하기 위해 각 캐시 위치에 유효 비트(valid bit)를 추가할 수 있다.
- valid bit가 설정된 경우 캐시 위치에 valid data가 있으며, 그 다음 tag를 참조하여 원하는 데이터인지 확인한다.
- valid bit가 설정되지 않은 경우, invalid이므로 tag를 확인하지 않는다.
'학교강의필기장 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조[21]: Direct Mapped Cache for the Real World (0) | 2023.06.22 |
|---|---|
| 컴퓨터구조[20]: Access a Direct Mapped Cache (0) | 2023.06.22 |
| 컴퓨터구조[18]: Data Hazard - Stall (0) | 2023.06.22 |
| 컴퓨터구조[17]: Data Hazard - Data Forwarding (0) | 2023.06.22 |
| 컴퓨터구조[16]: control signals for pipelined datapath (0) | 2023.06.22 |