
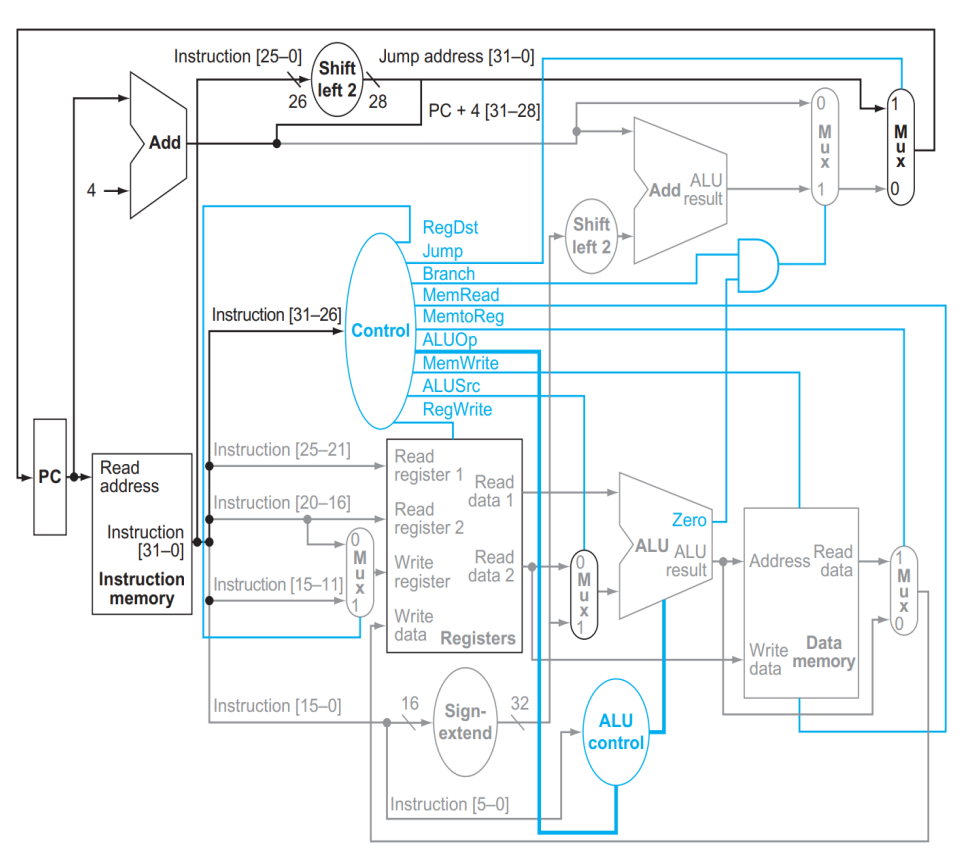
앞서 다룬, 위의 Data Path 구현방식은 모든 명령을 처리할 수 있지만, 비효율적이기에 쓰이지 않는다. 그러면 어떤 방법을 사용해야할까?
Pipelining
여러 가지 작업을 동시에 작동시킨다.
pipelining의 각 단계를 stage라고 한다.
stage란 명령어를 처리하는 동안 하드웨어 유닛에서 수행하는 활동이다.
- 처리량(throught - 단위 시간 내 처리할 수 있는 작업 수) 향상시킴
- 응답시간(response time - 각각의 단일 작업 수행 시간) 은 같음
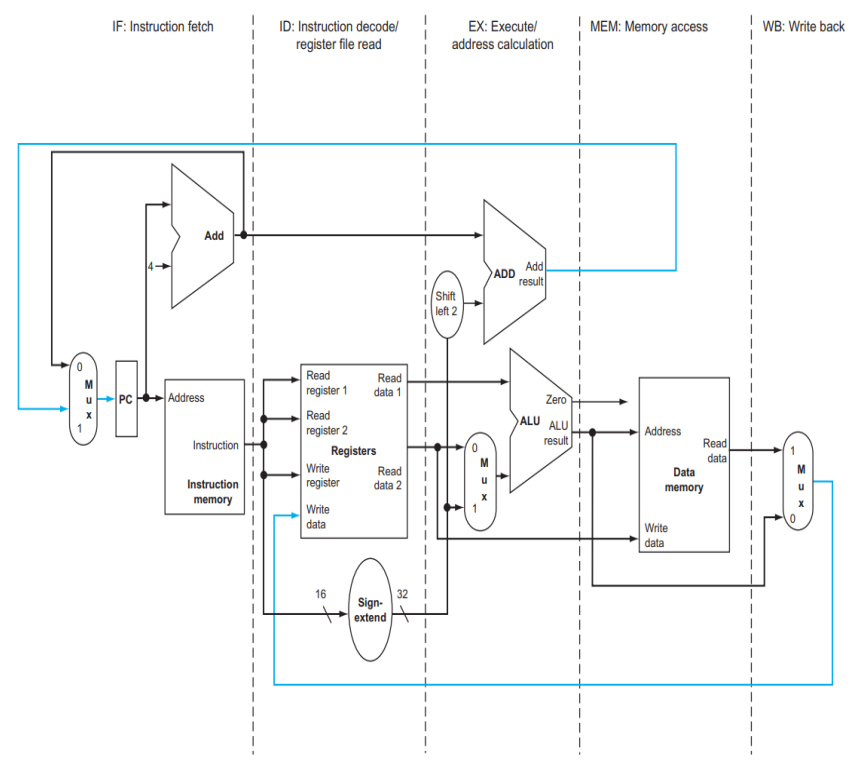
IF(Instruction fetch) : 메모리에서 명령을 가져옴
ID(Instruction decode/register file read) : 명령을 해독하면서 레지스터를 읽음
EX(Excute/address calculation) : 명령어 수행 또는 주소 계산을 수행함
MEM(Memory access) : 데이터 메모리에서 오퍼랜드에 액세스함 (메모리에서 데이터를 읽거나 씀)
WB(Write back) : 결과를 레지스터에 씀
명령어는 일반적으로 위 5단계를 순차적으로 수행하기에 파이프라이닝이 가능하다.
다만 역방향 데이터 이동이 있는 WB 스테이지(레지스터 파일에 삽입)와 EX 스테이지(분기에서 PC값 업데이트)에 예외가 있다.

위와 같이 명령어가 수행될 때,
@t에서 beq 명령어가 IF 스테이지에 올라온다.
@t+1에서는 beq 명령어가 ID로 이동한다. 그리고 lw 명령어가 IF 스테이지에 올라온다. 여기서 (PC+4)+4가 되지만, beq는 PC+4가 필요하다.
@t+2에서는 beq가 EX, lw가 ID로 이동한다. 여기서 sign-extended value는 10이 되는데 beq는 100이 필요하다.
이렇듯 스테이지에서 명령어의 정보는 다음 명령어가 스테이지에 들어올 때 손실되기에 해결이 필요하다.
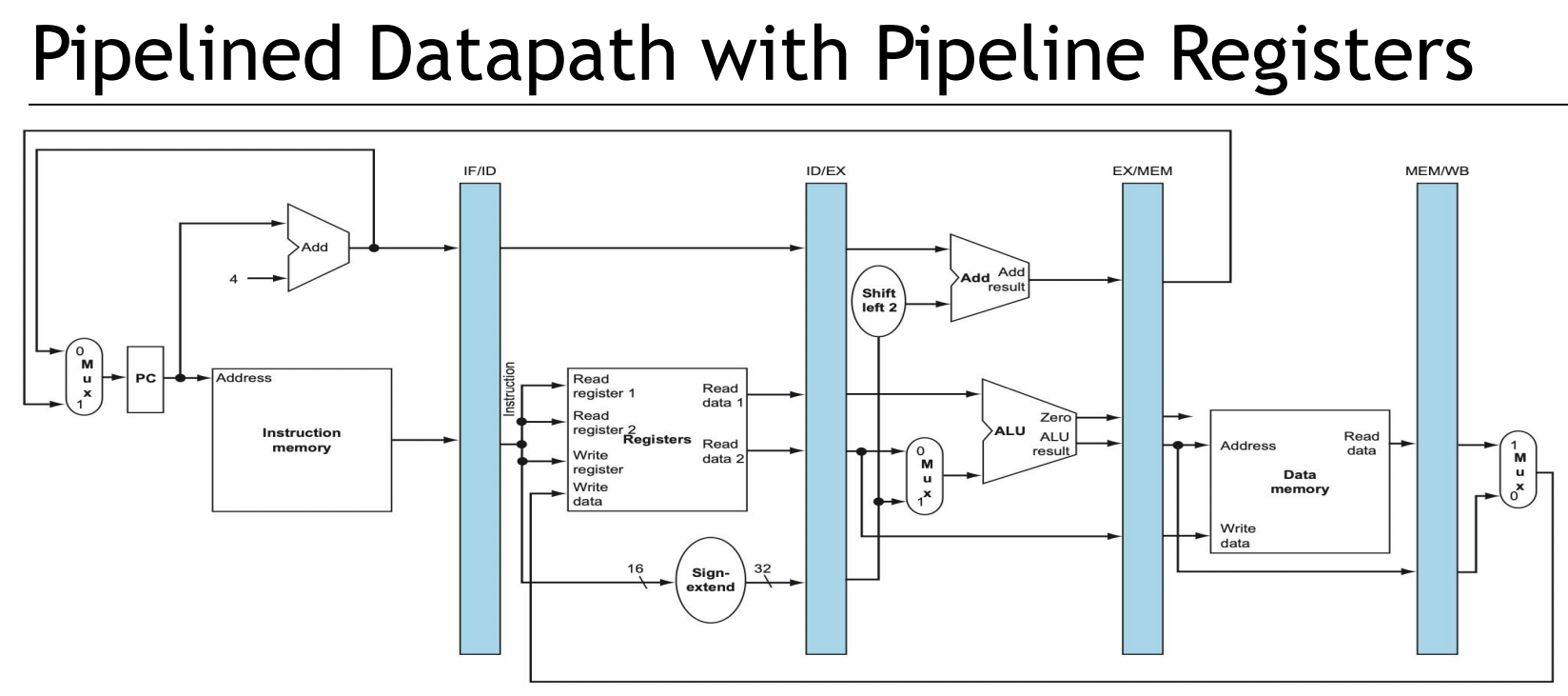
이를 해결하기 위해 각 스테이지 사이에는 파이프라인 레지스터가 존재한다.
예를 들어, IF 스테이지와 ID 스테이지 사이에는 IF/ID 스테이지가 있다.
모든 명령어는 한 번에 하나씩 다음 파이프라인 레지스터로 진행하고, 명령어가 진행되면서 필요한 정보는 다음 파이프라인 레지스터에 복사된다.
'학교강의필기장 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터구조[16]: control signals for pipelined datapath (0) | 2023.06.22 |
|---|---|
| 컴퓨터구조[15]: pipelined - lw, sw, bugfix (0) | 2023.06.22 |
| 컴퓨터구조[13]: Control Unit, Jump (0) | 2023.04.16 |
| 컴퓨터구조[12]: ALU Control Unit, Signal 정리 (0) | 2023.04.12 |
| 컴퓨터구조[11]: Execution of Branch Instruction on the DataPath (0) | 2023.04.10 |