
Real-Time CPU Scheduling
Event latency : 이벤트가 발생한 시점부터 해당 이벤트를 처리하는데 걸리는 시간
실시간 시스템의 성능에 영향을 미치는 두 가지 유형의 대기시간이 있다.
- interrupt latency : 인터럽트가 발생한 시점부터 해당 인터럽트를 처리하는 루틴이 시작되는 데까지 걸리는 시간
- dispatch latency : 현재 프로세스를 CPU에서 제거하고 다른 프로세스로 전환하는데 걸리는 시간

Dispatch Latency
1. 커널 모드에서 실행중인 프로세스의 선점(preemption) : 기존 프로세스를 실행중이던 CPU에게 그 실행을 중지시킴
2. 낮은 우선순위 프로세스가 높은 우선순위 프로세스가 필요로 하는 자원을 해제(release)하는 것. : CPU/메모리 확보
Priority-based 스케줄링
real-time 스케줄링을 위해선 preemptive, 우선순위 기반 스케줄링을 지원해야한다.
하지만 이것은 소프트 실시간이고, 하드 실시간을 보장하려면 데드라인을 준수해야한다.
주기적인(periodic) 프로세스는 일정한 간격으로 CPU를 필요로 한다.
processing time이 t, deadline이 d, period가 p => p주기마다 t 실행시간의 실행이 생기는데 d 안에 끝내야 함.
이 때 0<=t<=d<=p이다.
Admission-control algorithm은 프로세스가 스케줄러에게 deadline을 요청할 때,
받아들여서 주어진 시간 내에 종료를 보장하거나 불가능함으로 거부하는 것을 결정하는 알고리즘이다.
Rate Monotonic 스케줄링
주기적인 프로세스를 스케줄링, static priority policy + preemption 사용
주기가 짧을 수록 우선순위가 높고, 주기가 길수록 우선순위가 낮다.
즉, 주기가 짧은 프로세스를 우선 + 선점적으로 실행시킨다.
정적인 우선순위를 사용하는 알고리즘 가운데 최적해이다.
다만, N개의 프로세스를 스케줄링할 때 CPU 사용률은 N(2^(1/n)-1)을 넘을 수 없다.
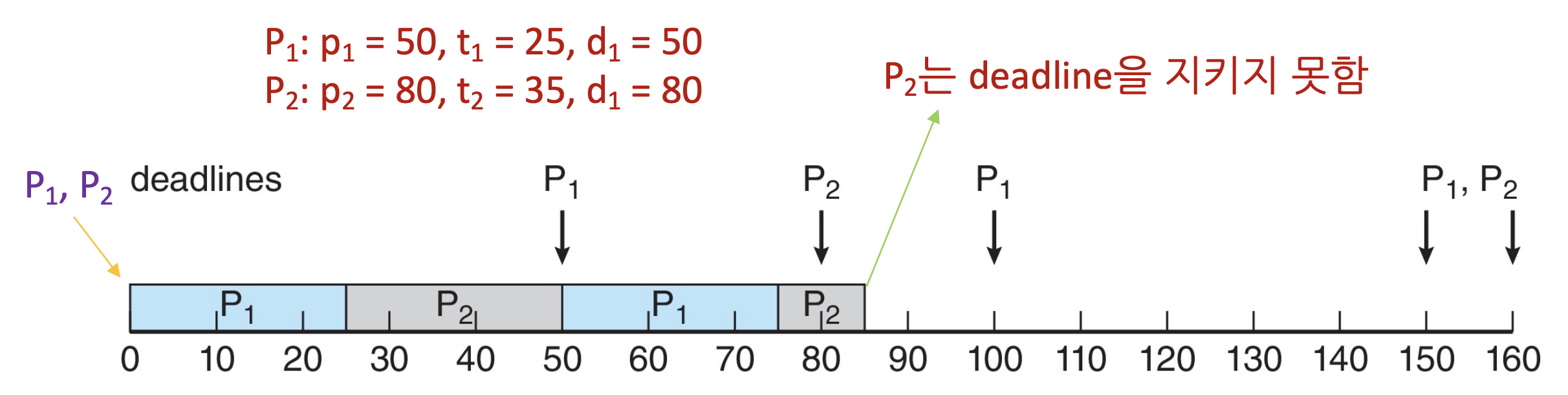
Earliest Deadline First 스케줄링 (EDF)
Rate Monotonic에선 주기가 짧은 것을 우선순위로 뒀지만, 여기선 데드라인이 짧게 남은걸 우선순위로 한다.

P1(p1 = 50, t1 = 25, d1 = 50), P2(p2 = 80, t2 = 35, d2 = 80)일 때의 예시이다.
EDF는 프로세스가 periodic일 필요도 없고 CPU burst가 일정할 필요도 없지만 스케줄러에게 deadline을 미리 알려줄 수 있어야한다.
이론상 CPU 사용률을 100%까지 올릴 수 있다.
Proportional Share 스케줄링
시스템 내 모든 프로세스들에게 T개의 CPU 자원이 할당된다.
애플리케이션은 N개의 자원을 할당받는다. (N < T)
각 애플리케이션은 전체 프로세서 시간의 N/T를 할당받게 된다.
만약 T=100,
Process A = 50, Process B = 15, Process C = 20 이라고 하면 CPU 사용률은 85%가 된다.
만약 여기서 Process D가 30을 요청하면 admission controller는 D의 요청을 거절한다.
POSIX Real-Time 스케줄링
POSIX.1b의 표준으로, real-time 스레드 관리를 위한 함수를 제공하는 API이다.
실시간 스레드를 위해 두 가지 스케줄링 클래스를 정의한다.
SCHED_FIFO : FCFS와 FIFO 큐를 사용해서 스레드를 스케줄링한다. 같은 우선순위 스레드에 대해 time-slicing이 없다.
SCHED_RR : 같은 우선순위 스레드에 대해 time-slicing이 발생한다 (round-robin)
O(1) Scheduler :: Linux Scheduling Through Version 2.5

커널 버전 2.5 이전에는 표준 UNIX 스케줄링 알고리즘의 변형을 사용했다.
2.5 버전 이후에는 상수 시간 O(1)의 스케줄링을 사용한다.
- Preemptive, 우선순위 기반
- 2개의 우선순위 범위 : time-sharing, real-time
- real-time의 범위는 0~99, nice 값은 100~140
- 전역 우선순위에 매핑되고, 수치적으로 낮은 값이 높은 우선순위
- 높은 우선순위는 더 큰 타임퀀텀을 받음.
- 타임퀀텀이 남아있는 한 task는 실행 가능하다. (active queue)
- 만약 타임퀀텀이 없으면 다른 모든 task가 그들의 타임퀀텀을 사용할 때까지 실행이 불가능하다. (expired queue)
- 모든 실행 가능한 task는 per-CPU run queue에 축적된다.
- * 두 개의 우선순위 배열 (active, expired)
- * 우선순위에 따라 task가 인덱싱됨
- * 더 이상 active가 없으면 active와 expired가 바뀜
- 단점 : 대화형 프로세스의 응답시간이 안좋음
Completely Fair Scheduler(CFS) :: Linux Scheduling in Version 2.6.23 +
스케줄링 클래스
- 각각에 특정 우선순위가 있다.
- 스케줄러는 가장 높은 스케줄링 클래스의 가장 높은 우선순위의 task를 선택한다.
- 고정된 타임퀀텀이 아니라 사용한 CPU 시간의 비율에 따라 계산된다.
- 2개의 스케줄링 클래스가 포함돼있고, 다른 클래스를 추가할 수 있다.
* 1. Default : CFS 사용
* 2. Real-Time
퀀텀은 -20에서 +19 까지의 nice value에 따라 계산된다. (낮은 값이 높은 우선순위)
task가 적어도 한 번 실행되어야 할 시간 간격인 target latency를 계산한다.
만약 활성화 된 task 개수가 증가하면, target latency가 증가할 수 있다.
CFS 스케줄러는 같은 실제 CPU 시간을 사용해도 우선순위가 낮은 프로세스의 가상 시간은 더 길게 측정하고, 높은 프로세스의 가상 시간은 더 짧게 측정한다.
다음 실행할 task를 결정하기 위해, 스케줄러는 가장 낮은 가상 실행 시간을 갖는 task를 선택한다.
물론 모두가 quantum을 사용하는 것은 보장해준다.
POSIX.1b에 따른 Real-Time 스케줄링 : Real-Time task는 정적인 우선순위를 갖는다.
Real-Time과 normal 우선순위는 전역 우선순위 체계에 매핑된다.

-20의 nice값은 전역 우선순위 100에 매핑된다.
+19의 nice값은 전역 우선순위 139에 매핑된다.
리눅스는 로드 밸런싱과 NUMA를 지원한다.
스케줄링 도메인은 서로 균형을 맞출 수 있는 CPU 코어의 집합이다.
도메인은 공유하는 것(캐시 메모리 등)에 따라 구성된다. 스레드가 같은 도메인 안에서만 이동하도록 유지하는 것이 목표다.
Window Scheduling
윈도우는 우선순위 기반의 선점형 스케줄링을 사용한다.
가장 높은 우선순위의 스레드가 다음에 실행된다.
디스패처(dispatcher)가 스케줄러이다.
스레드는 block될 때, time slice를 사용했을 때, 더 높은 우선순위의 스레드에 의해 선점될 때, 종료될 때까지 실행된다.
Real-Time 스레드는 그렇지 않은 스레드를 선점할 수 있다.
32단계의 우선순위 체계가 있다.
가변 클래스는 1-15, Real-Time 클래스는 16-31으로, Real-Time 클래스를 제외한 모든 클래스는 가변이다.
우선순위 0은 메모리 관리 스레드이다.
각 우선순위에 대한 큐가 존재한다.
실행 가능한 스레드가 없으면, idle 스레드를 실행한다.
Win32 API는 프로세스가 속할 수 있는 여러 우선순위 클래스를 식별한다.
주어진 우선순위 클래스 내의 스레드는 상대적 우선순위를 가진다.
우선순위 클래스와 상대적 우선순위가 결합되어 숫자 우선순위를 제공한다.
기본 우선순위는 클래스 내에서 NORMAL이다.
퀀텀이 만료되면 우선순위가 낮아지지만, 기본 우선순위 이하로는 내려가지 않는다.
가변 우선순위 스레드의 I/O대기가 완료되면, dispatcher가 우선순위를 향상시킴으로 I/O-bound thread를 CPU-bound thread보다 높은 우선순위를 갖게 한다.
wait가 발생하면 대기한 항목에 따라 우선순위가 높아진다. (가변 클래스에 속한 task만)
foreground 창은 3배의 우선순위 부스팅을 받는다.
윈도우7에서는 사용자 모드 스케줄링 (User-Mode-Scheduling)이 추가됐다.
- 응용 프로그램은 커널과 독립적으로 스레드를 생성관리한다.
- 많은 수의 스레드에 대해 더 효율적이다.
- UMS 스케줄러는 C++ Concurrent Runtime (ConcRT) 프레임워크와 같은 라이브러리에서 제공된다.
Algorithm Evaluation
OS에 CPU 스케줄링 알고리즘을 선택하는 방법은,
기준을 결정하고 알고리즘을 평가해야한다.
- 결정론적 모델링
- * 분석 평가의 유형
- * 특정 미리 결정된 작업 부하(workload)를 가져와서 해당 작업 부하에 대한 각 알고리즘의 성능을 정의한다.
Deterministic Evaluation
각 알고리즘에 대해 최소 평균 대기 시간을 계산.

이 방법은 간단하고 빠르지만, 입력 값에 대한 정확한 수치가 필요하고 해당 입력 값에만 적용될 수도 있다.
특정 작업 부하에서 각 알고리즘의 성능을 측정하기 위한 방법 중 하나로, 평균 대기 시간을 최소화하는 알고리즘을 선택하면 대기 시간을 최적화할 수 있다.
Queueing Models
프로세스의 arrival, CPU, I/O burst를 확률 분포로 모델링한다.
이를 위해 일반적으로 지수 분포를 사용하고, 평균 값을 기준으로 계산한다.
이 방법으로 평균 처리량, 이용률, 대기 시간 등을 계산할 수 있다.
컴퓨터 시스템은 "대기중인 프로세스의 큐를 가진 서버"와 비슷하다.
- arrive rates와 service rates를 알면 utilization, 평균 대기 queue 길이, 평균 대기 시간을 계산할 수 있다.
Little's Formula
n = 대기열의 평균 길이 (작업 수)
W = 대기 시간의 평균 (초)
λ = 대기열로 들어오는 작업의 평균 도착률 (작업/초) - 초당 작업 수
Little's law에 따르면 안정 상태에서 대기열에서 빠져나가는 프로세스 수는 도착하는 프로세스 수와 같다.
=> n = λ * W
모든 스케줄링 알고리즘과 arrival 분포에 대해서도 적용 가능하다.
평균 7개의 프로세스가 1초에 도착하고, 대기열에 평균 14개의 프로세스가 있으면 프로세스당 평균 대기시간은 2초가 된다.
Simulations
Queueing models에는 한계가 있고, 당연하게도 시뮬레이션이 더욱 정확하다.

- 컴퓨터 시스템의 프로그래밍된 모델
- Clock은 변수이다.
- 알고리즘 성능을 나타내는 통계를 수집한다.
- 시뮬레이션을 위한 데이터는 다음과 같이 수집된다.
- * 확률 분포에 따라 난수를 생성하는 난수 발생기 사용
- * 수학적 또는 경험적으로 정의된 분포
- * 실제 시스템에서 발생한 이벤트의 순서를 기록하는 trace 테이프
Implementation
물론 시뮬레이션에도 한계가 있다. 가장 확실한 건 새로운 스케줄러를 구현하고 실제 시스템에서 테스트하는 것이다.
- 비용과 위험이 높다.
- 환경이 다양하다. (성능을 예측하기 어렵다)
가장 유연한 스케줄러는 사이트별, 또는 시스템별로 수정할 수 있다. 또는 우선순위를 수정할 수 있는 API를 사용할 수 있다.
'학교강의필기장 > 운영체제론' 카테고리의 다른 글
| 운영체제론[11]: 스레드 동기화 (하드웨어 명령어) (0) | 2023.06.22 |
|---|---|
| 운영체제론[10]: 스레드 동기화 (이론편) (0) | 2023.06.22 |
| 운영체제론[8]: CPU 스케줄러 1 (0) | 2023.04.24 |
| 운영체제론[7]: 스레드 (0) | 2023.04.24 |
| 운영체제론[6]: 프로세스 간 통신, RPC (0) | 2023.04.24 |